I’ve recently come across a couple of scenarios with a similar issue: Googlebot was spending a significant portion of its crawl budget on discovering and crawling JSON requests.
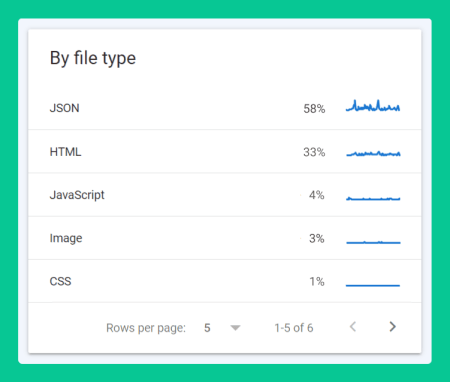
In one such scenario, Google Search Console’s Crawl Stats report was showing that Googlebot was spending 58% of its time crawling JSON requests! That’s over half of its time visiting the website!
In case you’re unfamiliar with JSON, it stands for JavaScript Object Notation. MDN explains that JSON “is commonly used for transmitting data in web applications (e.g., sending some data from the server to the client, so it can be displayed on a web page, or vice versa).” Typically, JSON is found in dynamic pages that require server interaction without refreshing the page.
In the scenario mentioned above, the Crawl Stats report URLs showed that the JSON requests were originating from an api triggered by a custom product search on the homepage.
To remain respectful to my client’s privacy, I cannot reveal any specific details. But, you can think of the dynamic webpage behaviour that you regularly come across on the web with app-like functionality, such as a store locator, hotel reservation form or an insurance quotation system. Many of these custom built components rely on JSON requests to pass data back and forth to a server via an API connection.
What you want to be mindful of is that the JSON file requests may be exposed to search bots, thereby potentially wasting the website’s crawl budget. In the long run it may also negatively impact indexation, discoverability of new content and the overall SEO performance of the site.
I would like to highlight that from experience, this type of issue tends to mostly impact larger websites with custom code and functionality. Less so with out-of-the-box CMSs, such as WordPress.
It also depends on the role that JSON data plays within your website’s architecture. PWAs (progressive web apps) tend to rely more heavily on passing data back and forth from the server, whereas less so for static websites.
Identify the issue
The most obvious place to start is by inspecting the Crawl Stats report found in Google Search Console.
Crawl Stats report
Open up the Crawl Stats report by navigating to the Settings dashboard of your Google Search Console account and click on ‘OPEN REPORT’. Next, observe the ‘By file type’ and ‘By Googlebot type’ boxes to see if you spot a high percentage of JSON requests being discovered by Googlebot. If so, you may potentially have a crawl budget issue and further investigation is required.
The crawl history URLs normally point you in the right direction. If still unsure, speak to your developers. They will more than likely be able to easily tell where the JSON requests are coming from.
Chrome DevTools
You may be able to find the JSON requests by investigating the Fetch/XHR filter in the network activity panel found in Chrome Devtools.
I’ll demonstrate how to identify JSON file requests using two separate sites that use different functionality. First, we’ll look at the Mercedes Bentz car dealership finder available on their shop.mercedes-benz.co.uk subdomain. Second, we’ll inspect the Virgin Atlantic flight finder available on their homepage (https://www.virginatlantic.com/).
But, before I begin, I want to highlight that I have no association with either of the Mercedes Bentz or Virgin Atlantic websites. In addition, I have no access to their Google Search Console accounts or know whether they have an issue with JSON file indexation. I’ve simply opted to use both examples because they mimic the same behaviour as the website’s I’ve worked on.
Now, let’s begin.
Mercedes Bentz car dealership finder
The dealership finder is the type of functionality you find on many national and international websites. The search functionality helps you to quickly find the nearest branch (or dealership in our Mercedes Bentz scenario). It looks like so:
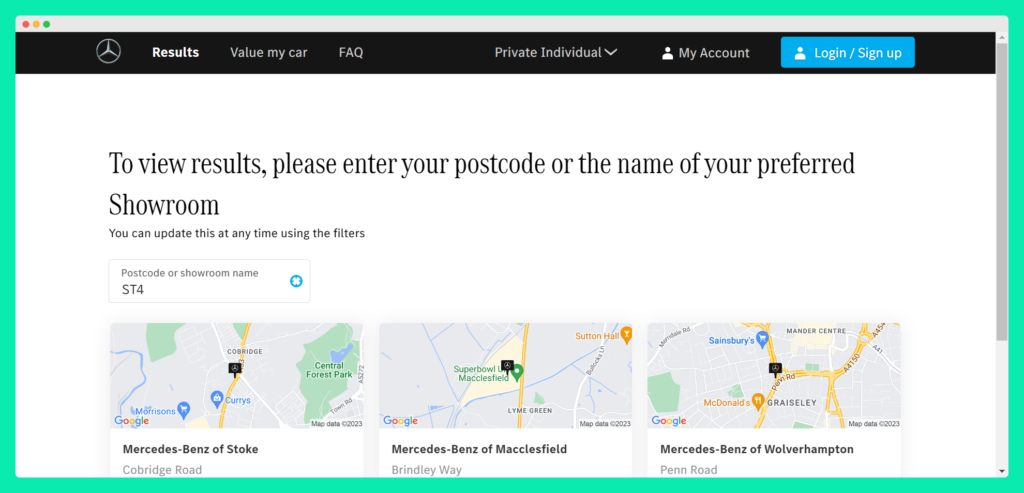
Looking at the code, we can see that the dealership finder is a custom built using the Vue.js and Nuxt.js. In addition, it relies on client-side JavaScript rendering to show the content. So, already we can see that this is a custom component built for Mercedez Bents as part of their user experience design. Now, let’s look at how this component fetches data to provide a seamless user experience on the front-end.
First, fire-up Chrome Devtools and navigate to the network panel. Click on the Fetch/XHR filter and make sure you can see the bottom of the list.
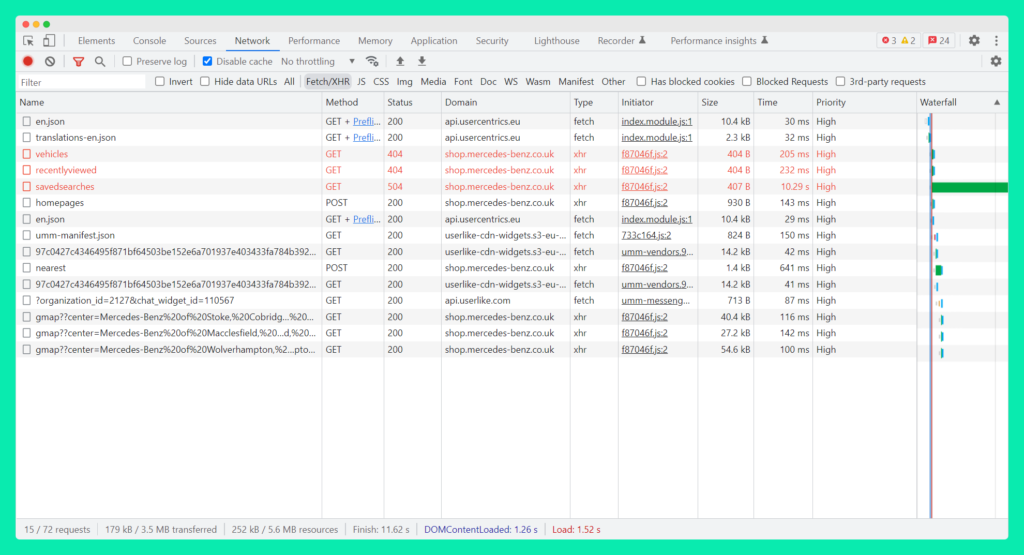
The search box on the page prompted me to enter my UK postcode to find the closest Mercedes Bentz car dealership in my area. I entered a fake Manchester-based postcode, and was immediately presented with the 3 nearest car dealerships to my location. Similar to any slick app functionality, the dealership finder was able to show results without having to refresh the page.
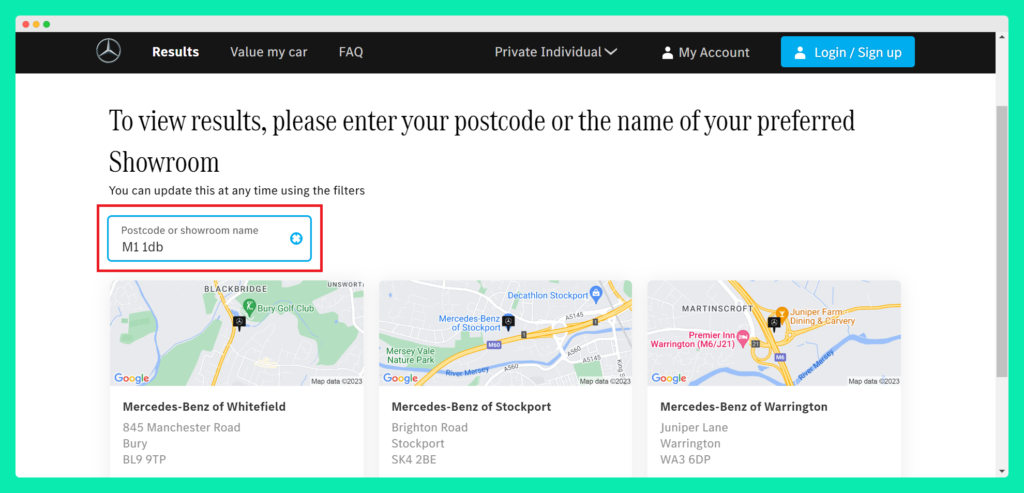
But, when I view the network activity, I can see that additional rows have appeared at the bottom of the network activity list.
The request I’m most interested in is the ‘nearest’ JSON file found towards the bottom of the list. You can see from the screenshot below that a POST request was sent to the server. The Payload sent with the POST request is the postcode I entered into the search box with instructions that it should return results within a 100 mile radius.
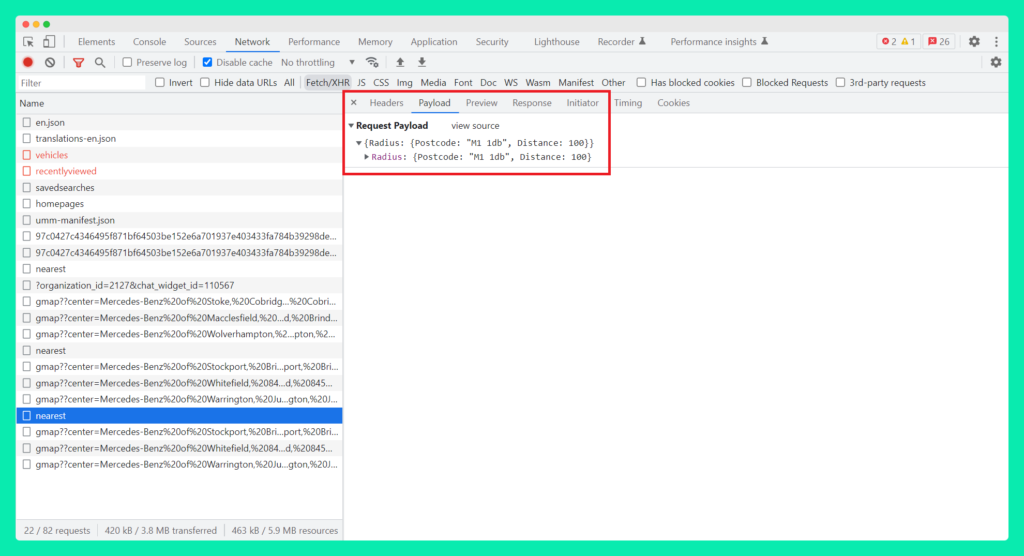
After which, the response from the server contained the list of dealership locations in the typical JSON key-value pair format, as seen in the Preview tab:
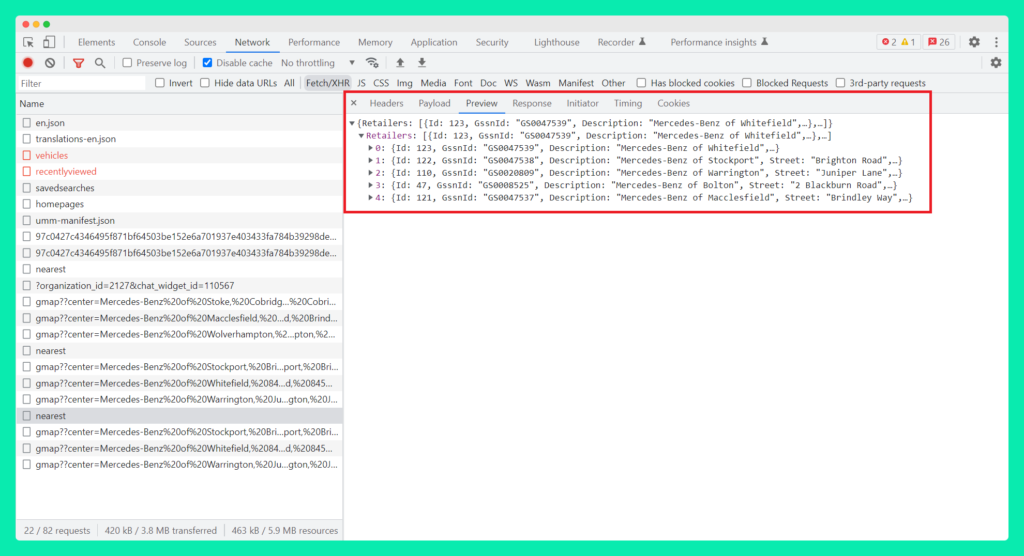
So what seemed like a seamless user experience interaction on the front-end, was achieved with a JSON network request and response from the server using a back-end API.
For our technical SEO purposes, however, it is the JSON URL that we’re more interested in as it’s what Googlebot may be picking up. In our Mercedes Bentz dealership finder example below, it is the Response Headers URL that may be showing up in your Google Search Console’s Crawl Stats Report:
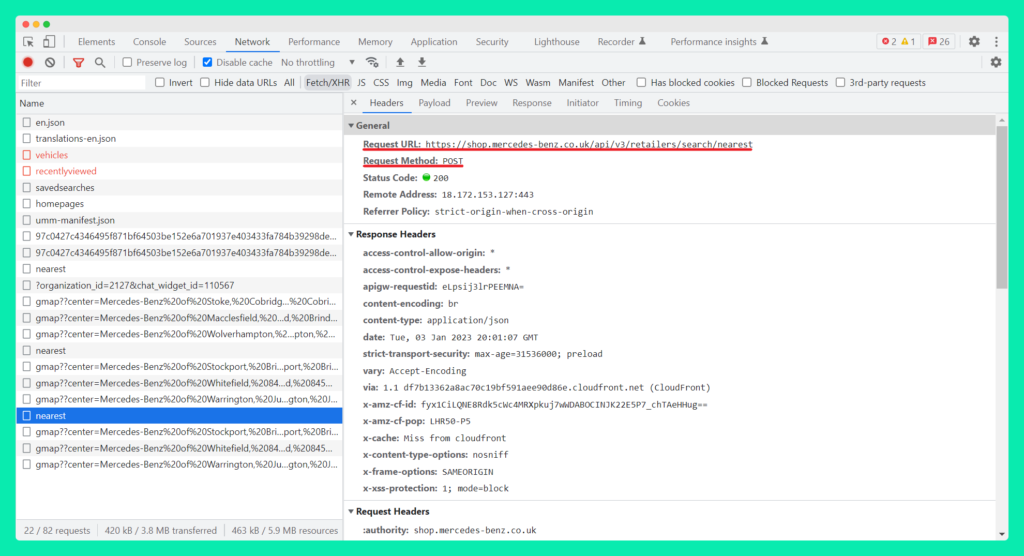
Interestingly, in our particular Mercedes Bentz dealership finder example, both the long page URL and the JSON api URL are potentially exposed to search bots. There are no canonicals, meta robots or robots.txt directives in sight. That means that there’s an open door policy to any search bot that decides to pay a visit. Now, without seeing their GSC account, it’s hard to judge if it’s a problem. But, it’s certainly a red flag. Being aware and understanding the extent of the problem is key.
The Virgin Atlantic Flight Finder
Let’s look at another example that seems to be implemented effectively; the Virgin Atlantic flight finder (as seen on their homepage).
To test the flight finder, I pretended to be interested in flights from London to New York in the middle of February and returning towards the end of the month.
I was taken to a search results page that showed the available flights within the selected timeframe, as seen below:
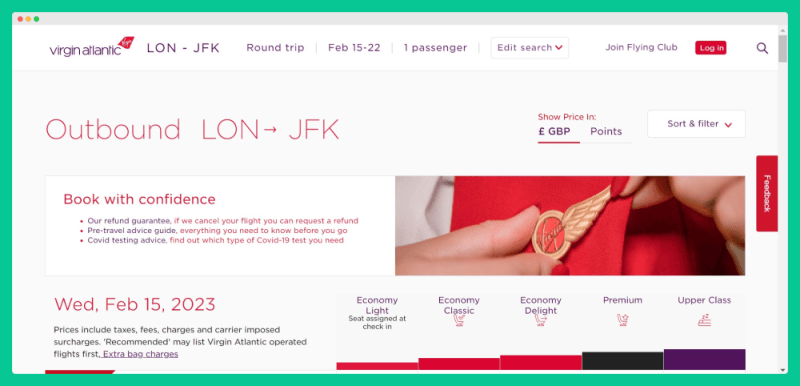
Behind the scenes, you can see that a POST request was sent to the server with the information I provided in the HTTP body:
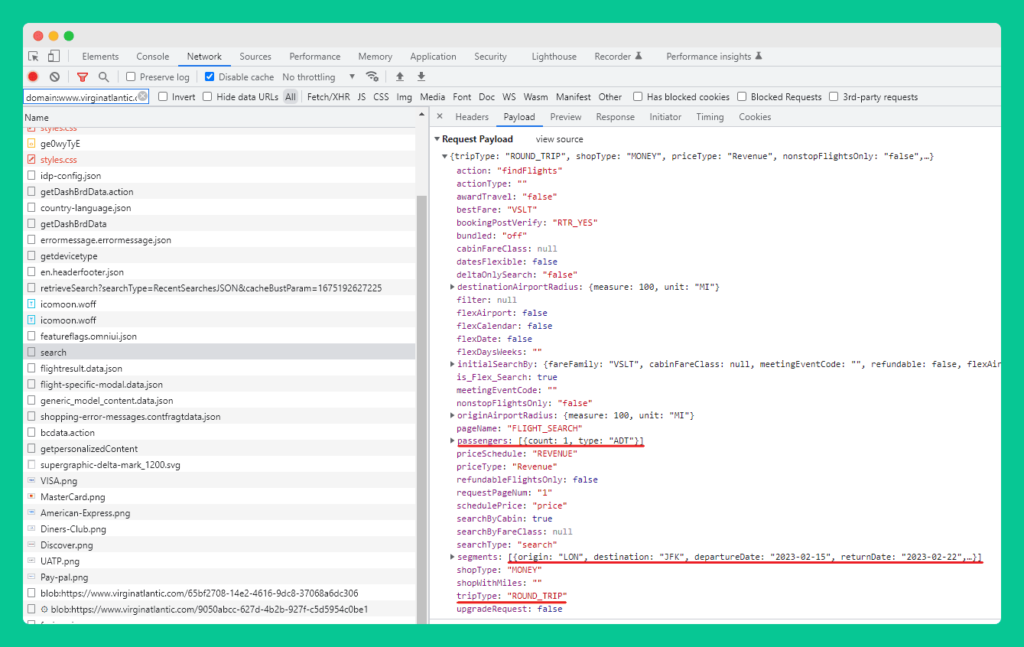
And, a preview of the response from the server shows the available flights that match my selected criteria:
As mentioned earlier, for our technical SEO purposes, it is the search results page URL or the JSON HTTP Headers URL that may be exposed to search bots.
In our test, the Virgin Atlantic search results page URL was the following:
And, you can see that the guys at Virgin Atlantic are aware of the potential index bloat if the URL is exposed to search. As the screenshot below shows (using the brilliant Robots Exclusion Checker by Sam Gipson), the team ensured that the URL path is blocked with a robots.txt directive, set with a noindex meta robots tag and canonicalized to a different URL! That’s 3 steps to ensuring that bots are blocked (and discouraged) from crawling the results page.
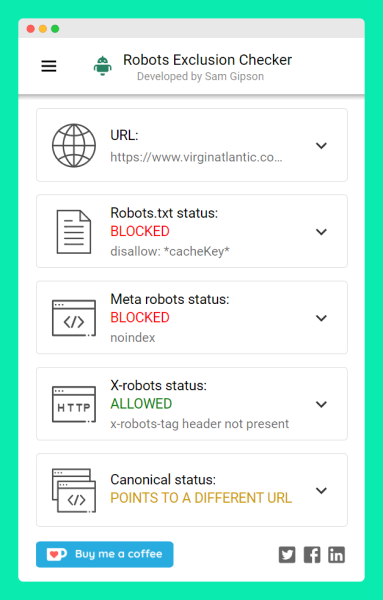
It’s important to note that even though the Virgin Atlantic team hasn’t blocked the JSON HTTP Headers URL from search bots, the flight search page is blocked so Googlebot should’t discover the JSON requests.
Technical SEO and JSON requests
As the examples above demonstrate, from a technical SEO point of view, it is important to know if JSON file requests are exposed to search bots. In most cases, there is little to be concerned about. But, as Victor Hugo famously wrote: “caution is the eldest child of wisdom”. And I suspect that Victor Hugo was a smart man so you better take heed of his advice!
Similar to the steps taken by the Virgin Atlantic team explained earlier, I ended up fixing the JSON indexation issue with a robots.txt disallow directive to stop search bots from crawling the search api URLs (not the JSON request URLs). Thankfully, the crawled JSON data didn’t seem to have a long-lasting negative impact on the website.
One thing to point out is that if your website shares similar custom built component functionality, the build and codebase will vary from the examples above. However, this guide should hopefully point you in the right direction. Your best option is to discuss the issue with the developers and see if JSON files are causing indexation havoc.
Importantly, I would advise you to avoid blocking access to JSON resources altogether as other parts of your website may need its functionality. Similar to CSS or JavaScript, blocking Googlebot (or any other search bot) from discovering those resources would more than likely result in a partially rendered page. At the very least, the search results found on the page are liable to be missing or show a continuous spinning loader icon.
As the two examples show, if your website implements custom search functionality that works with an API, it is likely that JSON files are part of the mix. As technical SEOs it is important to know where Googlebot (and other search bots) are spending their time crawling the site. If you identify it to be JSON requests, you should hopefully now have the know-how of where to check and how to resolve the issue.